Orchestrate
.procfwk
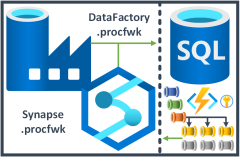
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
Stored Procedures
The following stored procedures are ordered by database schema then name.
Schema: procfwk
BatchWrapper
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @BatchId | uniqueidentifier |
| @LocalExecutionId | uniqueidentifier |
Role: When using the batch executions concept within the processing framework, this procedure establishes if a new or existing batch is required. If a batch is in a stopped state, its execution ID will be returned ready for a restart. If not, a new execution ID will be generated.
CheckForBlockedPipelines
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
Role: Used within parent pipeline as part of the sequential foreach activity this procedure establishes if any worker pipelines in the next execution stage are blocked. Then depending on the configured failure handing updates the current execution table before proceeding.
CheckForEmailAlerts
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @PipelineId | int |
Role: Assuming email alerting is enabled this procedure inspects the metadata tables and returns a simple true or false (bit value) depending on what alerts are required for a given worker pipeline Id. This check is used within the infant pipeline before any effort is spent constructing email content to be sent.
CheckMetadataIntegrity
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @DebugMode | bit |
Role: Called near the start of the parent pipeline this procedure serves the role of performing a series on basic checks against the database metadata ensuring key conditions are met before the orchestrator pipeline starts a new execution. See metadata integrity checks for more details.
CheckPreviousExeuction
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @BatchName | varchar |
Role: Inspects the current execution table for running worker pipelines as well as other unexpected record states and if found provides an output for the framework previous run clean up process. Otherwise, returns an empty dataset as is required by the lookup activity. The routine takes place as part of the parent pipeline execution.
CreateNewExecution
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @CallingOrchestratorName | nvarchar |
| @LocalExecutionId | uniqueidentifier |
Role: Once the parent pipeline has completed all pre-execution operations this procedure is used to set a new local execution Id (GUID) value and update the current execution table. For runtime performance an index re-build is also done by this procedure.
If using batch executions, instead of the procedure creating the execution ID it will be provided with it from the [BatchWrapper] stored procedure.
ExecutePrecursorProcedure
Schema: procfwk
Role: See Execution Precursor for details on this feature.
ExecutionWrapper
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @CallingOrchestrator | nvarchar |
| @BatchName | varchar |
Role: This procedure establishes what the framework should do with the current execution table when the parent pipeline is triggered. Depending on the configured properties this will then create a new execution run or restart the previous run if a failure has occurred.
If using batch executions the batch name should also be provided by the parent pipeline.
GetEmailAlertParts
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @PipelineId | int |
Role: When an email alert is going to be sent by the framework this procedure gathers up all required metadata parts for the send email function. This includes the recipient, subject and body. The returning select statement means exactly the format required by the function allowing the infant pipeline to pass through the content from the lookup activity unchanged.
GetFrameworkOrchestratorDetails
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @CallingOrchestratorName | nvarchar |
Role: As part of the Check Pipeline is Running utilties pipeline this procedure queries the metadata to return information about the framework orchestrator. This expects the calling orchestrator name to match the ‘IsFrameworkOrchestrator’ attribute in the Orchestrators table.
GetPipelineParameters
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @PipelineId | int |
Role: Within the child pipeline foreach activity this procedure queries the metadata database for any parameters required by the given worker pipeline Id. What’s returned by the stored procedure is a JSON safe string that can be injected into the execute pipeline function along with the other worker pipeline details.
In addition, the procedure updates the last value used attribute in the parameters table.
GetPipelinesInStage
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
Role: Called from the child pipeline this procedure returns a simple list of all worker pipelines to be executed within a given execution stage. Filtering ensures only worker pipelines that haven’t already completed successfully or workers that aren’t blocked are returned.
GetPropertyValue
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @PropertyName | varchar |
Role: This procedure is used by the orchestrators throughout the framework pipelines to return property values from a provided property name. This is done so the orchestrator activity can use the SELECT query output value directly, rather than this being an actual OUTPUT of the procedure.
GetStages
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
Role: Returns a distinct list of all enabled execution stages from the metadata to be used in the parent pipeline sequential iterations.
GetWorkerAuthDetails
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: For a given worker pipeline during an execution run of the processing framework, return the following:
- Tenant Id
- Subscription Id
- Service Principal Name (depending on configured SPN Handling)
- Service Principal Secret (depending on configured SPN Handling)
GetWorkerPipelineDetails
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: For a given worker pipeline during an execution run of the processing framework, return the following:
- Resource Group Name
- Orchestrator Name
- Orchestrator Type
- Worker Pipeline Name
GetWorkerDetailsWrapper
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: This procedure combines the output of the GetWorkerAuthDetails and GetWorkerPipelineDetails into a single request. The reason for this abstraction and refactoring is to overcome the pipeline side activity limitation by consolidating calls and outputs. The wrapper servers no other purpose.
ResetExecution
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @LocalExecutionId | uniqueidentifier |
Role: In the event of a processing framework restart this procedure archives off any unwanted records from the current execution table and updates the pipeline status attribute for any workers than didn’t complete successfully during the previous execution.
If using batch executions the procedure will also update the batch execution table using the execution ID provided.
SetErrorLogDetails
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @LocalExecutionId | uniqueidentifier |
| @JsonErrorDetails | varchar |
Role: For a failed worker pipeline the error message details will be passed to this procedure in raw JSON form. Then parsed and inserted into the database error log table. See error details for more information on this feature.
SetExecutionBlockDependants
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @PipelineId | int |
Role: When using the dependency chain feature for failure handling this procedure queries the metadata and applies a ‘blocked’ status to any downstream (dependant) worker pipelines in the current execution table.
SetLogActivityFailed
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
| @CallingActivity | varchar |
Role: In the event of a wider Azure platform failure where a pipeline activity failures for unexpected reasons this procedure attempts to update and leave the current execution table with an informational status. This status will typically be the activity that has resulted in the failure outcome. A common use for this procedure is when hitting external resources like the Azure Functions activities within the infant pipeline.
SetLogPipelineCancelled
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
| @CleanUpRun | bit |
Role: Updates the current execution table setting the pipeline status attribute to cancelled for the provided worker Id. Also blocks downstream pipelines depending on the configured failure handling behaviour.
SetLogPipelineChecking
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: During the parent pipeline clean up process. Updates the current execution table setting the pipeline status attribute to checking for the provided worker Id.
SetLogPipelineFailed
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
| @RunId | uniqueidentifier |
Role: Updates the current execution table setting the pipeline status attribute to failed for the provided worker Id. Also blocks downstream pipelines depending on the configured failure handling behaviour.
SetLogPipelineLastStatusCheck
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: During the infant pipeline Until activity upon each iteration this procedure updates the current execution table with the current date/time in the last check attribute. This offers some visability on how many wait iterations have occurred for a given worker pipeline execution.
SetLogPipelineRunId
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
| @RunId | uniqueidentifier |
Role: Once a given worker pipeline is in progress the orchestrator run Id will be returned from the Azure Function and added to the current execution table using this stored procedure.
SetLogPipelineRunning
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: Updates the current execution table setting the pipeline status attribute to running for the provided worker Id.
SetLogPipelineSuccess
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: Updates the current execution table setting the pipeline status attribute to success for the provided worker Id.
SetLogPipelineUnknown
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
| @CleanUpRun | bit |
Role: Updates the current execution table setting the pipeline status attribute to unknown for the provided worker Id. Also blocks downstream pipelines depending on the configured failure handling behaviour.
SetLogPipelineValidating
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
| @PipelineId | int |
Role: Updates the current execution table setting the pipeline status attribute to validating for the provided worker Id.
SetLogStagePreparing
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @ExecutionId | uniqueidentifier |
| @StageId | int |
Role: Updates the current execution table setting the pipeline status attribute to preparing for all worker pipelines in the provided execution stage Id.
UpdateExecutionLog
Schema: procfwk
| Parameter Name | Data Type |
|---|---|
| @PerformErrorCheck | bit |
| @LocalExecutionId | uniqueidentifier |
Role: Called at the end of the parent pipeline as the last thing the processing framework does in the metadata database this procedure validates the contents of the current execution table. If all workers were successful the data will be archived off to the execution log table. Otherwise an exception will be raised.
If using batch executions the procedure will also update the batch execution table and delete from the current execution table rather than truncating.
IF([procfwk].[GetPropertyValueInternal]('UseExecutionBatches')) = '0'
BEGIN
TRUNCATE TABLE [procfwk].[CurrentExecution];
END
ELSE IF ([procfwk].[GetPropertyValueInternal]('UseExecutionBatches')) = '1'
BEGIN
DELETE FROM [procfwk].[CurrentExecution] WHERE [LocalExecutionId] = @ExecutionId;
END
Schema: procfwkHelpers
AddPipelineDependant
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @PipelineName | nvarchar |
| @DependantPipelineName | nvarchar |
Role: Applies a relationship between an upstream and downstream worker pipeline while conforming to metadata integrity constraints.
AddPipelineViaPowerShell
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @ResourceGroup | nvarchar |
| @OrchestratorName | nvarchar |
| @OrchestratorType | char |
| @PipelineName | nvarchar |
Role: This procedure is used as part of the solution PowerShell scripts when populating the metadata database with a set of worker pipelines from an existing orchestrator instance. For more details on this feature see how to Apply ProcFwk To An Existing Orchestrator.
AddProperty
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @PropertyName | varchar |
| @PropertyValue | nvarchar |
| @Description | nvarchar |
Role: Performs an upsert to the database properties when a new or existing processing framework property is provided. Internally, a merge statement applies the change to the table.
AddRecipientPipelineAlerts
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @RecipientName | varchar |
| @PipelineName | nvarchar |
| @AlertForStatus | nvarchar |
Role: Assuming the recipient already exists in the metadata this procedure adds the required link for a given worker pipeline and the requested status values.
The ‘AlertForStatus’ parameter can be a comma separated list if multiple status values are required.
AddServicePrincipal
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @OrchestratorName | nvarchar |
| @OrchestratorType | char |
| @PrincipalId | nvarchar |
| @PrincipalSecret | nvarchar |
| @SpecificPipelineName | nvarchar |
| @PrincipalName | nvarchar |
Role: If the database property for storing service principals is set to use insert them into the database, this procedure encrypts the parameter values provided and adds them to the database while conforming to metadata integrity constraints.
AddServicePrincipalUrls
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @OrchestratorName | nvarchar |
| @OrchestratorType | char |
| @PrincipalIdUrl | nvarchar |
| @PrincipalSecretUrl | nvarchar |
| @SpecificPipelineName | nvarchar |
| @PrincipalName | nvarchar |
Role: If the database property for storing service principals is set to use Azure Key Vault, this procedure attempts to validate the parameter values provided and adds them to the database while conforming to metadata integrity constraints. ___
AddServicePrincipalWrapper
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @OrchestratorName | nvarchar |
| @OrchestratorType | char |
| @PrincipalIdValue | nvarchar |
| @PrincipalSecretValue | nvarchar |
| @SpecificPipelineName | nvarchar |
| @PrincipalName | nvarchar |
Role: Depending on the configuration of the SPN handling this procedure passes off parameter values to one of the following stored procedures:
- AddServicePrincipal
- AddServicePrincipalUrls
CheckStageAndPiplineIntegrity
Schema: procfwkHelpers
Role: This procedures uses the optional attribute ‘LogicalPredecessorId’ within the pipelines table to review and suggest updates to the structure of the worker pipeline metadata considering execution stages and upstream/downstream dependants. The output of the procedure is purely for information.
DeleteMetadataWithIntegrity
Schema: procfwkHelpers
Role: Performs an ordered delete of all metadata from the database while conforming to metadata integrity rules.
DeleteMetadataWithoutIntegrity
Schema: procfwkHelpers
Role: Performs a blanket delete of all database contents for tables in the procfwk schemas.
DeleteRecipientAlerts
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @EmailAddress | nvarchar |
| @SoftDeleteOnly | bit |
Role: Removes or disables a given email recipient from the metadata tables while conforming to metadata integrity rules.
DeleteServicePrincipal
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @OrchestratorName | nvarchar |
| @OrchestratorType | char |
| @PrincipalIdValue | nvarchar |
| @SpecificPipelineName | nvarchar |
Role: Removes a given service principal from the metadata tables while conforming to metadata integrity rules.
GetExecutionDetails
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @LocalExecutionId | uniqueidentifier |
Role: Used as runtime helper offered more details about the current execution run with additional table joins and summary information.
GetServicePrincipal
Schema: procfwkHelpers
| Parameter Name | Data Type |
|---|---|
| @OrchestratorName | nvarchar |
| @OrchestratorType | char |
| @PipelineName | nvarchar |
Role: Depending on the configured properties this procedure queries the service principal table and returns credentials that the orchestrator can use when executing a worker pipeline. See worker SPN storage for more details.
SetDefaultAlertOutcomes
Schema: procfwkHelpers
Role: Adds the default email alerting outcome values to the metadata table used as part of the processing framework development environment.
SetDefaultOrchestrators
Schema: procfwkHelpers
Role: Adds a set of default orchestrator values to the metadata table used as part of the processing framework development environment.
SetDefaultPipelineDependants
Schema: procfwkHelpers
Role: Adds a simple set of default pipeline dependencies to the metadata table used as part of the processing framework development environment.
SetDefaultPipelineParameters
Schema: procfwkHelpers
Role: Adds a set of default pipeline parameter values to the metadata table used as part of the processing framework development environment.
SetDefaultPipelines
Schema: procfwkHelpers
Role: Adds a set of default pipeline values to the metadata table used as part of the processing framework development environment.
SetDefaultProperties
Schema: procfwkHelpers
Role: Adds all default framework property values to the metadata table used as part of the processing framework development environment.
SetDefaultRecipientPipelineAlerts
Schema: procfwkHelpers
Role: Adds a set of default alerting relationship values to the metadata table used as part of the processing framework development environment.
SetDefaultRecipients
Schema: procfwkHelpers
Role: Adds several default recipient values to the metadata table used as part of the processing framework development environment.
SetDefaultStages
Schema: procfwkHelpers
Role: Adds a set of default execution stage values to the metadata table used as part of the processing framework development environment.
SetDefaultSubscription
Schema: procfwkHelpers
Role: Adds a default subscription value to the metadata table used as part of the processing framework development environment.
SetDefaultTenant
Schema: procfwkHelpers
Role: Adds a default tenant value to the metadata table used as part of the processing framework development environment.
Schema: procfwkTesting
Add300WorkerPipelines
Schema: procfwkTesting
Role: Applies a set of 300 worker pipelines with parameters and SPN details to the metadata database as part of the setup for an integration run stress test.
CleanUpMetadata
Schema: procfwkTesting
Role: Used as a wrapper for the helper stored procedures DeleteMetadataWith*** to add a empty all metadata from the database. Typically called as part of integration test one time tear downs. See testing for more details on this feature.
GetRunIdWhenAvailable
Schema: procfwkTesting
| Parameter Name | Data Type |
|---|---|
| @PipelineName | nvarchar |
Role: During the integration tests to cancel a running worker pipeline this procedure queries the current execution table waiting for a Run Id value to become available. Once found, the wait iteration breaks and provides the first value found.
ResetMetadata
Schema: procfwkTesting
Role: Used as a wrapper for the helper stored procedures SetDefaultxxx to add a complete set of default metadata to the database. Typically called as part integration test one time setups. See testing for more details on this feature.