Orchestrate
.procfwk
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
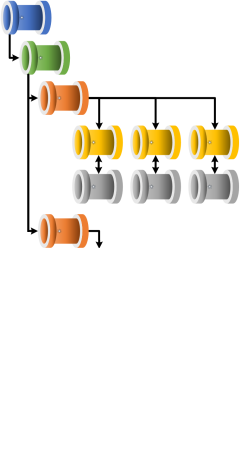
Execution Batches
Batches operate within the processing framework as an optional level of execution that sit above stages. They can be represented with the following 3 tier hiearchy of execution:
- Batches
- Stages
- Workers
- Stages
The key feature of batches is to have concurrent parent pipeline executions configured using only metadata updates.
For context, batches can be used within the processing framework, for example, if you wish to trigger a set of stages/worker processes that fall or overlap within a given frequency. Hourly, daily or monthly.
At deplopment time it is expected that triggers will be configured separately within each orchestrator using different schedules, each hitting the framework parent pipeline, but with different ‘Batch Name’ parameter values passed according to the batch execution required.
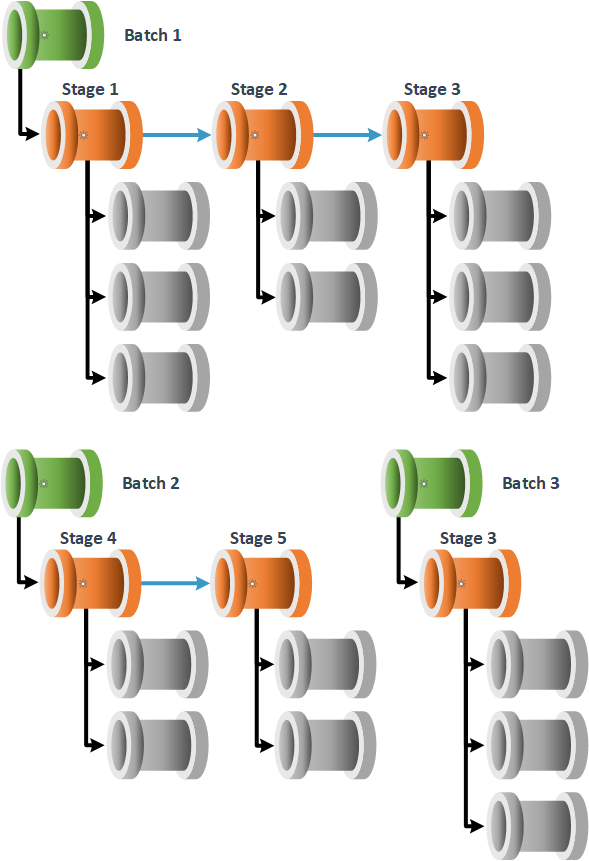
A batch can further be defined with the following statements:
- Batches are optionally available within the framework, enabled and disabled via the database properties table.
- Distinct batches can be triggered concurrently from the framework parent pipeline. This uses the Batch Name parameter to separate executions.
- The same batch name cannot be triggered concurrently.
- A batch name must be enabled to be used at execution time using the [Enabled] attribute within the Batches metadata table.
- A batch can be linked to 1 or many execution stages using the [BatchStageLink] table.
- A batch must have at least one execution stage that is enabled.
- Different batches can call and use the same execution stage. If reusing a subset of worker pipelines is required, these should be separated into secondaly execution stages.
- The batch execution feature cannot be enabled while a none batch execution run is still in progress or incomplete.
- A batch must be completed with a successful status before it is called again. Otherwise the batch will attempt to restart the execution run. This also takes into account the ‘OverideRestart’ configuration property.
- Execution stages can be considered as orphaned if not part of an execution batch once this feature is enabled.
Using Batches
To use execution batches the following four updates should be made to processing framework:
- Set the database property ‘UseExecutionBatches’ to 1, true, enabled.
- Add batch information to the table [procfwk].[Batches].
- Add links between the execution batch and execution stages using the table [procfwk].[BatchStageLink].
- Trigger the parent pipeline providing the new batch name value as a pipeline parameter.
Please check out a demostration of this feature on my YouTube channel:
