Orchestrate
.procfwk
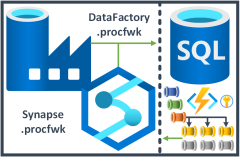
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
Database
 The SQL database within the processing framework solution is critical in providing the orchestrator with all the metadata required for both runtime configuration and execution of worker pipelines.
The SQL database within the processing framework solution is critical in providing the orchestrator with all the metadata required for both runtime configuration and execution of worker pipelines.
It is expected that this resource be made available to the orchestrator as a Linked Service connection. Beyond that the database itself can be hosted by any type of SQL resource, even using an on-premises SQL Server instance connected via a Hosted IR if needed. That said, for the solution development environment an Azure SQL Database (PaaS offering) is used with an Azure Logical SQL Instance.
For medium sized implementations (300 worker pipelines across 3 execution stages) of the processing framework it is recommended to start with an S2 service tier or equivilant to provide enough compute for all metadata calls made from the orchestrator are served in a timely manor and without effecting platform runtime performance. Database storage will greatly depend on the amount of metadata you have and how long you wish to store data in the execution log tables.
The metadata database can be viewed as a whole in the below database diagrams. These are separated into two main groups.
Metadata & Configuration Tables
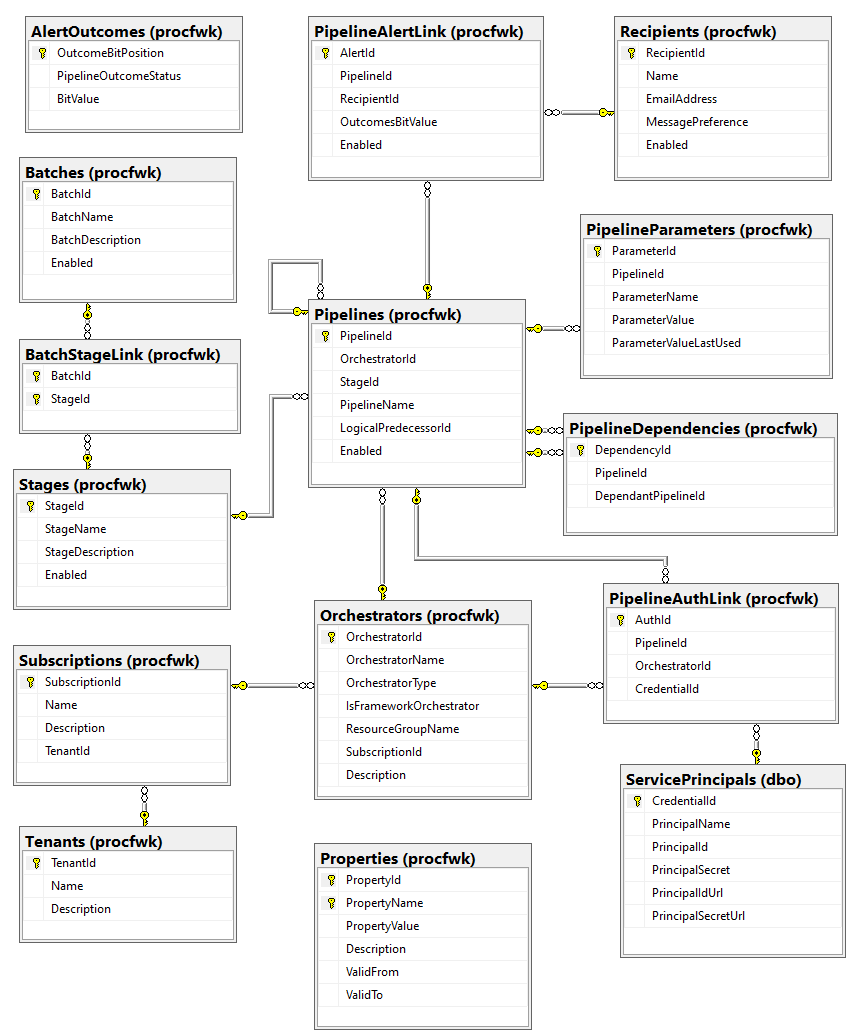
Runtime Execution & Logging Tables