Orchestrate
.procfwk
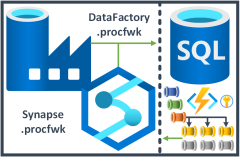
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
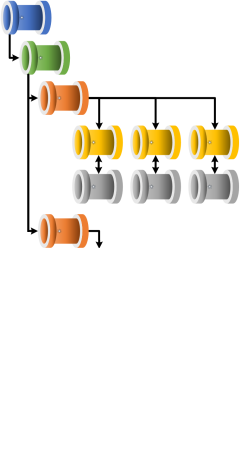
Execution Stages
An execution stage can be defined as an isolated set of work that the processing framework is given to complete.
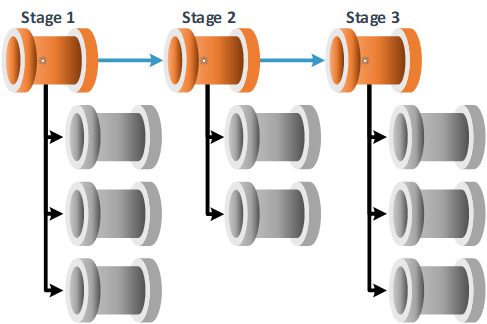
These sets of work can be considered in the following ways, or defined with these conditions:
- A stage must be set to enabled in the metadata to be called by the processing framework.
- A stage contains one or many lower level worker pipelines.
- All work done within a single execution stage should not have any inter dependencies.
- Work done within a single execution stage will be called in parallel using the framework scale out processing capabilities.
- Worker pipelines with inter dependencies should be added to a subsequent execution stage(s).
- All available execution stages will be processed sequentially.
- The metadata stage ID attribute is used to define the order in which execution stages are processed.
- A given execution stage must complete before the next execution stage can be called.
- Configurable failure handling behaviour allows pipelines within an execution stage to fail and still call a subsequent stage.
- The database stored procedure ‘GetStages’ is used by the parent pipeline to return a distinct, ordered and enabled list of all execution stages in scope for running during a given framework execution run.
- An Azure service level limitation in the pipeline Lookup activity means only 5,000 execution stages can currently be handled by the processing framework. If you require more execution stages, please log a feature request via the GitHub repository issues area, here.