Orchestrate
.procfwk
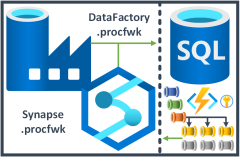
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
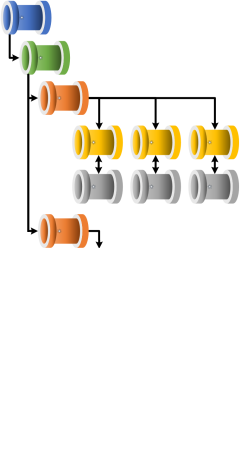
Pipelines
Pipelines are a common component of the orchestrator used as a logic housing for groups of Activities needed to perform a process or task.
Given the interchangeable nature of different orchestrators within the processing framework. Pipelines are also interchangeable and use a common code base for currently support Azure resources.
Regardless of the orchestrator type the framework uses the following set of generational pipeline concepts and definitions.
Grandparent - Environment Setup
 Role: Optional level platform setup, for example, scale up/out compute services ready for the framework to run.
Role: Optional level platform setup, for example, scale up/out compute services ready for the framework to run.
The grandparent level within the processing framework solution is completely optional. It is expected that here higher level platform operations are performed to make the environment ready before the core framework is triggered. This maybe include a set of data ingestion processes.
Parent - Framework/Batch Executor
 Role: Execution run wrapper and execution stage iterator.
Role: Execution run wrapper and execution stage iterator.
The parent pipeline is primarily used to setup and/or cleanup the next execution run for the framework, depending on the current database Properties. It runs precursor operations and resets the metadata where required in either new or restart scenarios.
As a secondary function at this level the parent pipeline initiates the first ForEach activity used to sequentially iterate over Execution Stages. For each iteration the framework will also check for any workers that may have blocked processing due to worker pipeline failures.
Finally, the parent is responsible for getting/setting of the Local Execution ID which is then used throughout all downstream pipelines when making updates to the metadata current execution table.
Child - Stage Executor
 Role: Scale out triggering of worker pipelines within the execution stage.
Role: Scale out triggering of worker pipelines within the execution stage.
The child pipeline is called once per execution stage. It is small in structure and has a simple purpose to hit the second level ForEach activity, this is used to trigger all worker pipelines within the current execution stage in parallel. This Scale Out Processing is achieved using the default behaviour for the Data Factory activity.
Infant - Worker Executor
 Role: Worker executor, monitor and reporting of the outcome for the single worker pipeline.
Role: Worker executor, monitor and reporting of the outcome for the single worker pipeline.
Once a worker pipeline has been triggered by the child one infant pipeline per worker is used to handle the execution and monitoring of its run. The infant uses an Until activity to iterate over the status of its given worker pipeline waiting until it completes. Once complete the infant will update the metadata with the relevant status information and error details in the event of a worker failure.
The time between infant check status iterations can be configured via the database Properties table.
The infant (ironically) is the largest pipeline and has the most activities within the framework, doing the most work. This is to consistency and controllably deal with the execution of the worker pipelines. From a boiler plate code perspective, it is also the pipeline that gets reused/called the most.
The infant pipeline could be used in isolation in trigger a worker pipeline if required.
Workers
 Role: Anything specific to the process needing to be performed.
Role: Anything specific to the process needing to be performed.
Worker pipeline internals fall outside the remit of the processing framework. They exist only as items registered within the metadata plus associated parameters (if required). Worker pipelines are expected to contain whatever activities are required for a given process and should not use content from the processing framework metadata database other than the pipeline level parameters provided at runtime.
By design worker pipelines can be decoupled from the main orchestration pipelines above and live in separate Data Factory resources.
Utilities (Internal Workers)
 Utility pipelines (or internal workers) are small reusable packages within the processing framework that support the above generational pipelines. These sit within the framework orchestrator instance in the sub folder ‘_ProcFwkUtils’
Utility pipelines (or internal workers) are small reusable packages within the processing framework that support the above generational pipelines. These sit within the framework orchestrator instance in the sub folder ‘_ProcFwkUtils’
For the framework to run the following utility pipelines are used:
Throw Exception
This utility provide a simple way of throwing an exception within Data Factory using a T-SQL raise error to throw an exception when required as part of the wider control flow activities. The T-SQL raise rrror message information is then exposed as a pipeline parameter, shown below.
RAISERROR('@{pipeline().parameters.Message}',16,1);
Email Sender
This pipeline provides a simple abstract over the send email function with request body items exposed as easy to use pipeline parameters.
Check For Running Pipeline
See Pipeline Already Running for more details.