Orchestrate
.procfwk
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
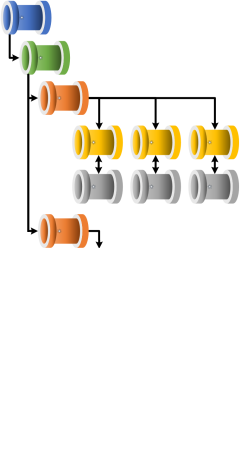
Orchestrator Types
The processing framework supports the use of both common pipeline orchestration services within Azure:
When implementing the processing framework it is designed so each orchestrator type can be completely interchangeable in terms of the orchestrators roles.
The key to this handling is controlled through the [procfwk].[Orchestrators] database table where all orchestration services need to be registered. The table attribute OrchestratorType is pivital in how the framework handles and calls pipelines for each service.
| Value | Orchestration Service |
|---|---|
| ADF | Azure Data Factory |
| SYN | Azure Synapse Analytics |
When implemented its possible for framework pipelines to be housed in Azure Data Factory, with worker pipelines running in Azure Synapse Analytics and vice versa. Or, having all pipelines housed within a single orchestration service. This includes support for cross tenant and subscription execution.
The only restriction is that all framework pipelines (Grandparent, Parent, Child, Infant and Utilities) reside within the same orchestration service and are identified by the orchestrators database table using the ‘IsFrameWorkOrchestrator’ attribute.
Interchangeable Orchestrator Types
The following 6 different orchestrator setups supported by the processing framework in terms of the orchestrators role and pipeline location.
Using batch executions offers theorical overlap for framework pipelines calling a single metadata database. However, this is not currently supported and has not been tested.
To ensure metdata integrity, a new check and database contraint exists to ensure within the orchestrators table the attribute IsFrameworkOrchestrator is always set of only one orchestrator entry.


![]()

![]()



![]()
![]()