Orchestrate
.procfwk
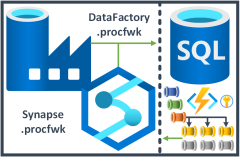
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
Service Tiers & Limitations
Service Tiers
When deploying Azure resources always check with the person paying the bill!
In the case of the processing framework, the intention is to keep resources running as cheaply as possible. That said, the following is expected in terms of service tiers.
| Resource | Tier | Comments |
|---|---|---|
| Data Factory | v2 | Data Flow activities are not used as part of the processing framework so the default auto resolving Azure Integration Runtime can be used. |
| Synapse | N/A | Data Flow activities are not used as part of the processing framework so the default auto resolving Azure Integration Runtime can be used. |
| SQL Database | S2 | Using a provisioned service tier rather than serverless is recommended to avoid framework start up failures. |
| Functions App | Consumption Plan | Deployments done using code to a Windows host wit support for .Net Core 3.1 |
| Key Vault | Standard | Optional. |
The above service tiers have been bench marked running 300 worker pipelines, across 3 execution stages and 600 worker pipelines in two concurrent batches.
Service Limitations
The service limitations for the processing framework are inherited from Microsoft’s Azure Resource limitations. For the service tiers described above the first resource limitation you’ll likely hit will be for the orchestrator and the allowed number of pipeline activity runs per subscription and IR region.
| Limit Detail | Default Limit | Maximum Limit |
|---|---|---|
| Concurrent External activity runs per subscription per Azure Integration Runtime region. External activities are managed on integration runtime but execute on linked services, including Databricks, stored procedure, HDInsights, Web, and others. This limit does not apply to Self-hosted IR. | 3,000 | 3,000 |
| Concurrent Pipeline activity runs per subscription per Azure Integration Runtime region. Pipeline activities execute on integration runtime, including Lookup, GetMetadata, and Delete. This limit does not apply to Self-hosted IR. | 1,000 | 1,000 |
Source: https://github.com/MicrosoftDocs/azure-docs/blob/master/includes/azure-data-factory-limits.md
Within the framework defining internal and external activities can be difficult as this greatly depends on your worker pipelines and how long the infant pipeline is going to wait between complete status checks.
However, for a single execution stage, in a single batch, triggered from the parent pipeline using the default linked service/integration runtime setup and with with 50 concurrent worker pipeline. This will generate approximatley 700 activity runs within your framework Data Factoy instance. Using a 30 second infant pipeline wait duration.
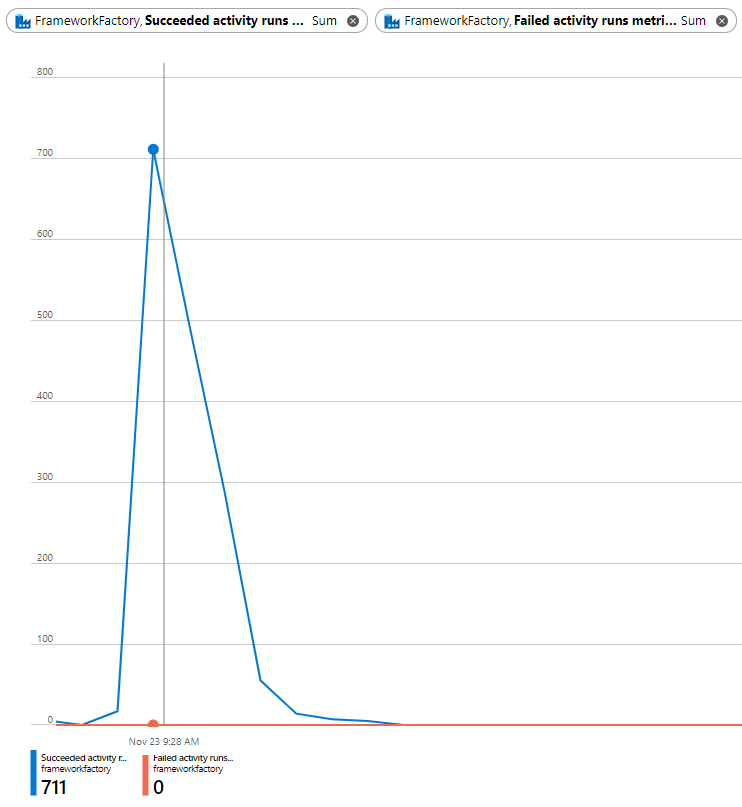
At the point of testing, no other orchestrator instances were present on an isolated Azure Subscription and worker pipelines were running in a different Azure tenant.
This gives a theorical maximum degree of parallelism of 285 worker pipelines.
It is possible to push these service limitations by creating a custom set of Azure Integration Runtimes for the orchestrator and tuning specific parts of the framework pipelines to reduce the number of internal activity calls. If you hit activity run failures during a framework execution run and this is isolated within a subscription please email paul@mrpaulandrew.com for support. To that end, stress testing of the framework has been done using 20 concurrent execution batches, each calling 50 worker pipelines to achieve a maximum degree of parallelism of 1000 worker pipelines. This was done under ideal conditions and using a custom configuration of 4x Azure Integration Runtimes, in different Azure Regions.
Framework Activities (Internal vs External)
To inform the above activity limitations, it should be noted that for each framework pipeline the following internal and external activities exist, shown in the table below. These count values are static based on an extract of an ARM template from a current framework Data Factory instance. Therefore, in a given pipeline IF or SWITCH conditions may apply at runtime meaning only some external activities are called.
| Pipeline Name | Type | Activity Count |
|---|---|---|
| 01-Grandparent | External | 0 |
| 01-Grandparent | Internal | 1 |
| 02-Parent | External | 3 |
| 02-Parent | Internal | 7 |
| 03-Child | External | 0 |
| 03-Child | Internal | 2 |
| 04-Infant | External | 7 |
| 04-Infant | Internal | 10 |
| Check For Running Pipeline | External | 0 |
| Check For Running Pipeline | Internal | 11 |
| Email Sender | External | 1 |
| Email Sender | Internal | 0 |
| Throw Exception | External | 0 |
| Throw Exception | Internal | 1 |
Or, to aggregate this by pipeline using the orchestration activity type names, see below.
| Pipeline Name | Type | ActivityCount |
|---|---|---|
| 01-Grandparent | ExecutePipeline | 1 |
| 02-Parent | ExecutePipeline | 1 |
| 02-Parent | ForEach | 2 |
| 02-Parent | Lookup | 3 |
| 02-Parent | SetVariable | 1 |
| 02-Parent | SqlServerStoredProcedure | 3 |
| 03-Child | ForEach | 1 |
| 03-Child | Lookup | 1 |
| 04-Infant | AzureFunctionActivity | 2 |
| 04-Infant | IfCondition | 2 |
| 04-Infant | Lookup | 4 |
| 04-Infant | SetVariable | 2 |
| 04-Infant | SqlServerStoredProcedure | 5 |
| 04-Infant | Switch | 1 |
| 04-Infant | Until | 1 |
| Check For Running Pipeline | Filter | 1 |
| Check For Running Pipeline | IfCondition | 2 |
| Check For Running Pipeline | Lookup | 3 |
| Check For Running Pipeline | SetVariable | 4 |
| Check For Running Pipeline | Switch | 1 |
| Email Sender | AzureFunctionActivity | 1 |
| Throw Exception | Lookup | 1 |