Orchestrate
.procfwk
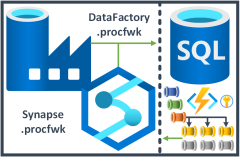
A cross tenant metadata driven processing framework for Azure Data Factory and Azure Synapse Analytics achieved by coupling orchestration pipelines with a SQL database and a set of Azure Functions.
- Overview
- Contents
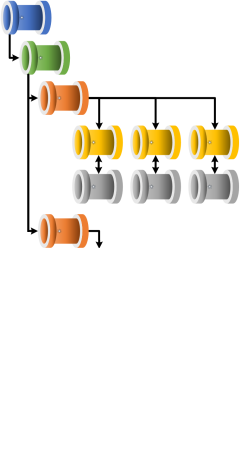
Scale Out Processing
 The scaling out (parallel processing) of worker pipelines within an execution stage is achieved by using the orchestrators default behaviour for the ForEach activity. This is set as a batch count value in the activity properties.
The scaling out (parallel processing) of worker pipelines within an execution stage is achieved by using the orchestrators default behaviour for the ForEach activity. This is set as a batch count value in the activity properties.
When provided with an array of values to iterate over the ForEach activity can do this either sequentially, or by creating parallel threads for all iterations requires.
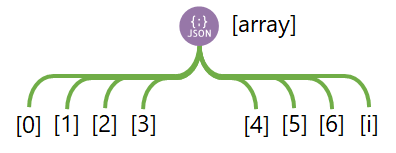
The default behaviour for the ForEach activity is to create a batch of 20 parallel iterations. However, the framework pipelines increase this to the service maximum of 50 parallel iterations within a batch.
- If within an execution stage there are less than 50 worker pipelines to be called they will all be done in parallel and the unallocated iterations within the maximum array (batch) size ignored.
- If within an execution stage there are more than 50 worker pipelines to be called they will be called as soon as space becomes available within the batch.
In all cases the order in which worker pipelines are picked up for execution within a stage is handled by the orchestrator.
The primary reason within the framework for the child pipeline is to deliver this scaled out ForEach behaviour for the worker pipelines. The degree of worker parallelism can be seen using the reporting database view, WorkerParallelismOverTime.